(Hands-On) Add a Bugfix to Reproduced Snapshot
1. Remove column
To remove this column, edit the cell to add this command:
train_df.drop('Survived', axis=1, inplace=True);
train_df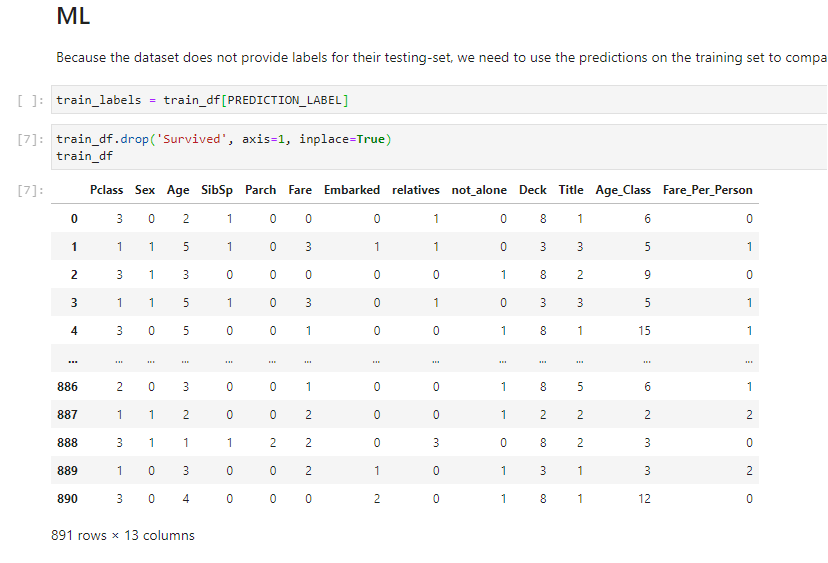
2. Enable Kale
The cell we added previously is by default a pipeline step cell type and since we have defined no name, it will be merged with the featureengineering step. Enable Kale and ensure the cell that removes the Survived labels is part of the featureengineering pipeline step. The cell will have the same outline color.
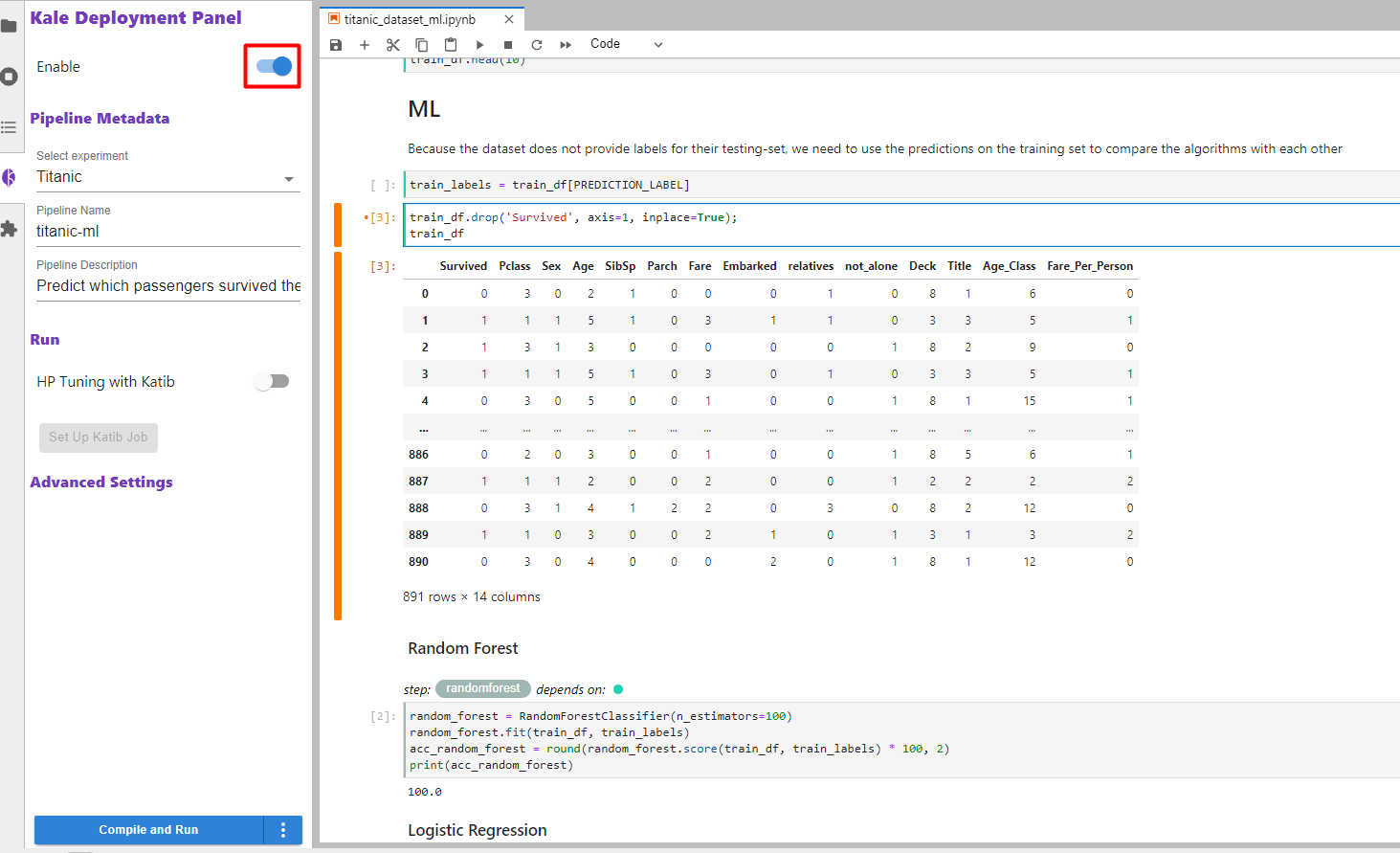
3. Rerun the pipeline
Run the pipeline again by clicking on the Compile and Run button.
Click the link to launch the Kubeflow Pipelines UI and view the run.
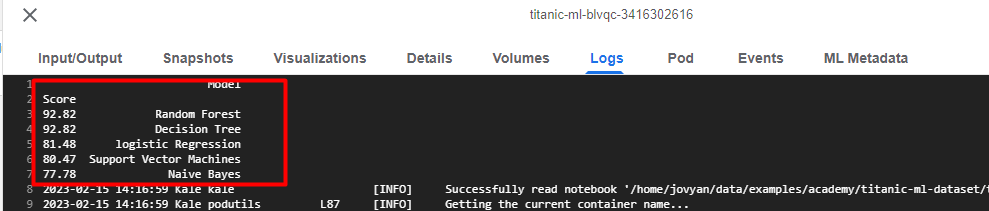
Wait for the results step to complete and view the logs to see the final results. You now have realistic prediction scores!