(Hands-On) Convert Your Notebook to a Kubeflow Pipeline
The following video is an excerpt from a live session dedicated to reviewing the Jupyter notebook that makes up the solution for this particular Kaggle competition example.
After watching this video you will deploy a Kubeflow pipeline to create a model for Titanic Disaster Survivor Prediction based on the Jupyter notebook.
1. Enable Kale
Enable Kale by clicking on the Kale icon in the left pane:
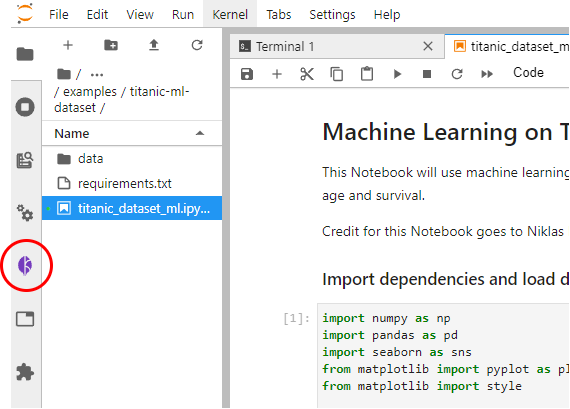
2. Explore per-cell dependencies
See how multiple cells can be part of a single pipeline step, and how a pipeline step may depend on previous steps:
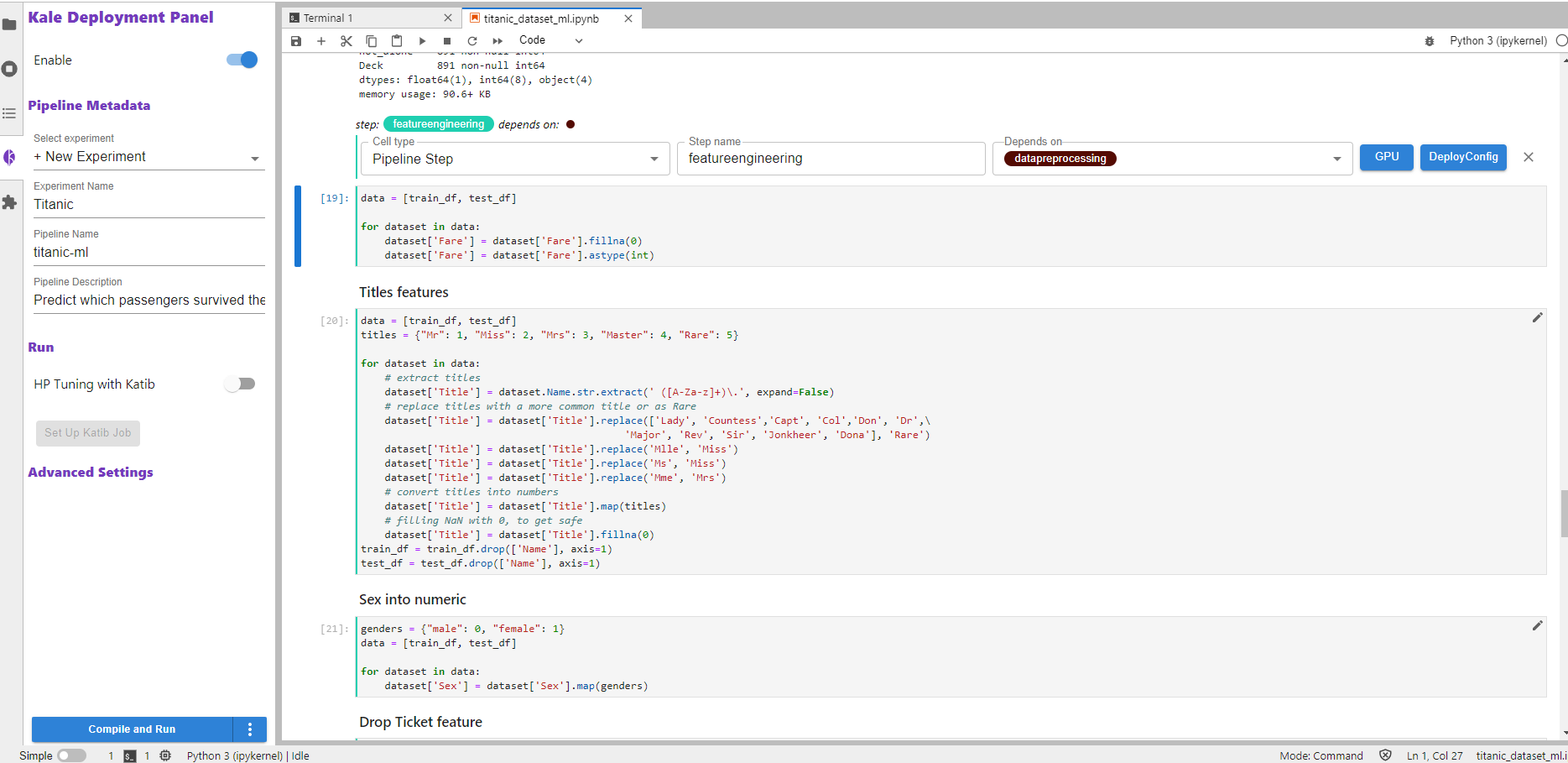
3. Compile and run
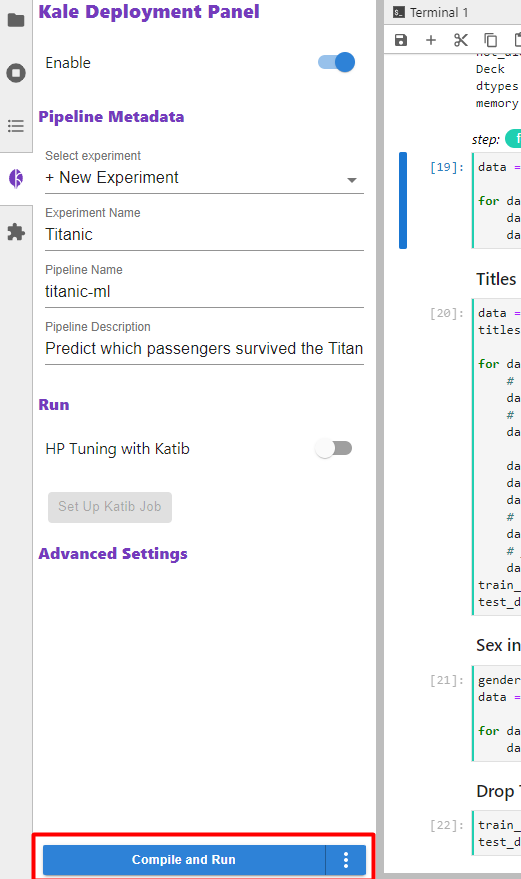
Click the Compile and Run button:
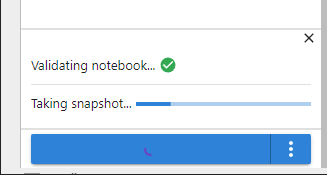
Observe the progress of the snapshot.
Observe the progress of the pipeline run.
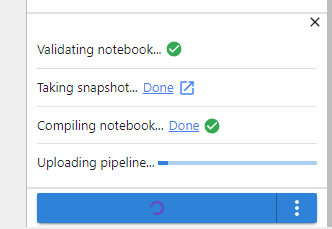
4. View the run
Click the link to launch the Kubeflow pipelines UI and view the run.
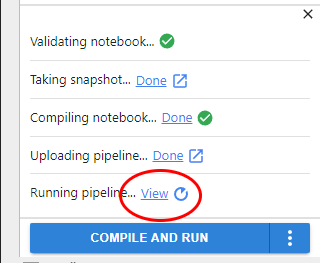
Wait for it to complete.
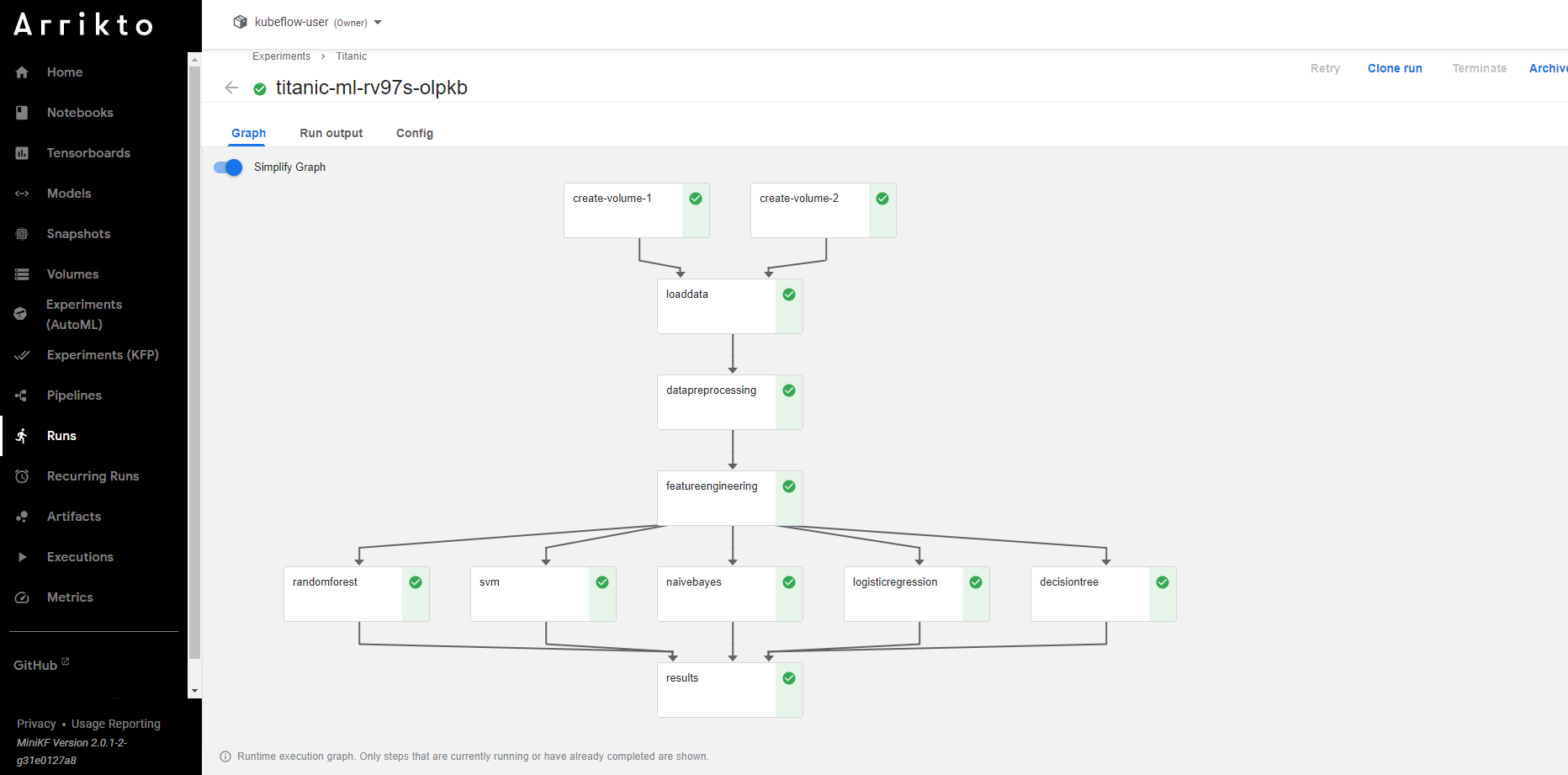
Congratulations! You just ran an end-to-end Kubeflow pipeline starting from your notebook! Note that we didn’t have to create a new Docker image, although we installed new libraries. Rok took a snapshot of the whole notebook, including the workspace volume that contains all the imported libraries. Thus, all the newly added dependencies were included. We will explore Rok and Snapshotting further in the next section.