(Hands-On) Convert Your Notebook to a Kubeflow Pipeline
The following video is an excerpt from a live session dedicated to reviewing the Jupyter notebook that makes up the solution for this particular Kaggle Competition example.
After watching this video you will deploy a Kubeflow pipeline to create a model for Covid-19 mRNA Vaccine Degradation Prediction based on the Jupyter notebook.
1. Enable Kale
Click on the Kale icon in the left pane of the notebook:
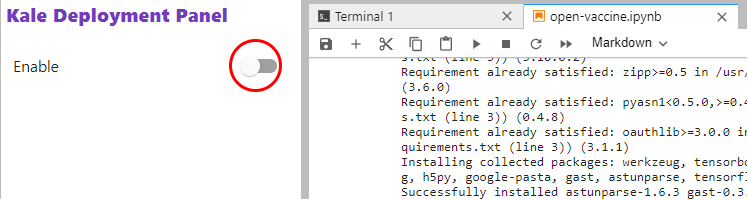
Enable Kale by clicking on the slider in the Kale Deployment Panel:
2. Explore the per-cell dependencies
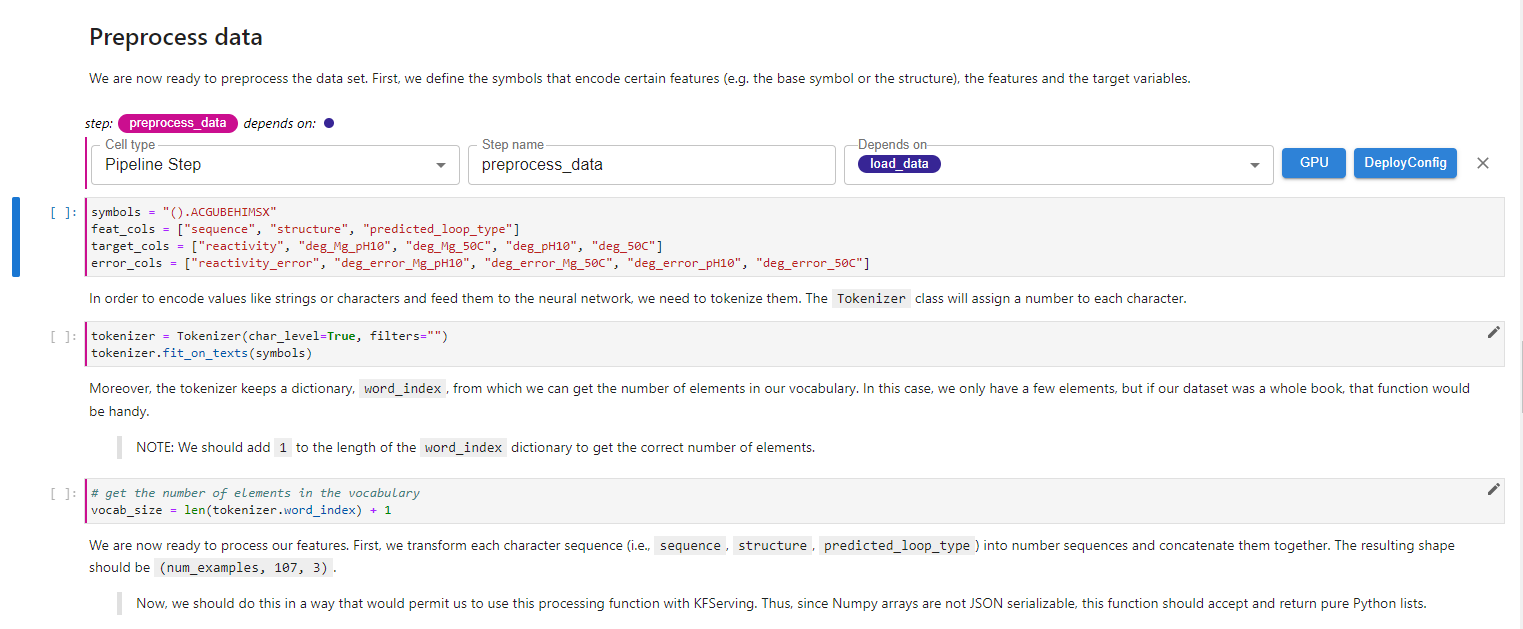
Explore the per-cell dependencies within the notebook. See how multiple notebook cells can be part of a single pipeline step, as indicated by color bars on the left of the cells, and how a pipeline step may depend on previous ones, as indicated by depends on labels above the cells. For example, the image below shows multiple cells that are part of the same pipeline step. They have the same magenta color and depend on a previous pipeline step named load_data.
3. Compile and run
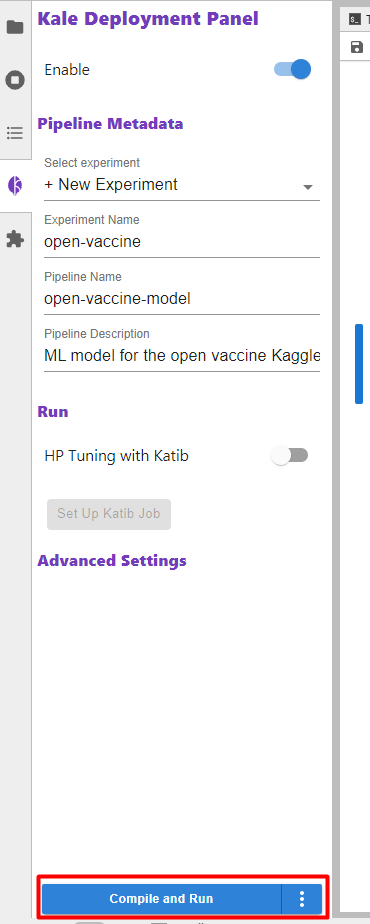
Click on the Compile and Run button:
Now Kale takes over and builds your notebook, by converting it to a KFP pipeline. Also, since Kale integrates with Rok to take snapshots of the current notebook’s data volume, you can watch the progress of the snapshot. Rok takes care of data versioning and reproducing the whole environment as it was when you clicked the Compile and Run button. This way, you have a time machine for your data and code, and your pipeline will run in the same environment where you have developed your code, without needing to build new Docker images.
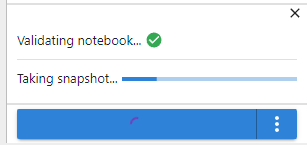
4. View the run
The pipeline was compiled and uploaded to Kubeflow Pipelines. Now click the link to go to the Kubeflow Pipelines UI and view the run.
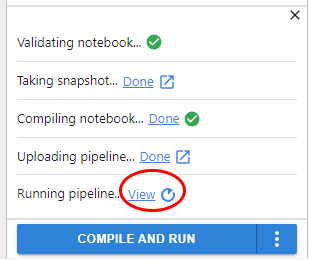
The Kubeflow Pipelines UI opens in a new tab. Wait for the run to finish.
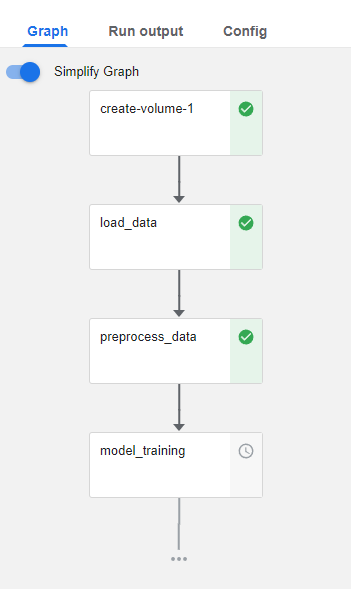
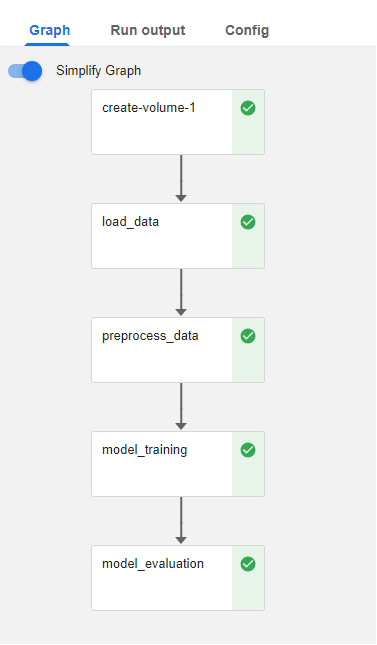
Congratulations! You just ran an end-to-end pipeline in Kubeflow Pipelines, starting from your notebook!
The following video is an excerpt from a live session dedicated to reviewing the Kubeflow pipeline that is generated by the Jupyter notebook that makes up the solution for this particular Kaggle Competition example.