Introduction to Distributed Training
There are several techniques to run distributed deep learning training. In this course, we employ the so-called “Data Parallel (DP)” approach. In DP you train the same model across independent workers on separate data batches and aggregate the model weights or gradients with a reduced operator.
The Kubeflow PyTorch operator is a Kubeflow component that can orchestrate PyTorch deep learning distributed jobs. A PyTorch distributed job consists of a series of Pods. There is always one master Pod, and at least one worker Pod. As the name suggests, the master is responsible for coordination. In the most common scenario, the Pods communicate during the training process to synchronize the gradients before updating the weights of the model.
In order to describe and submit such a job, you need to write a PyTorchJob CR (YAML file), providing run configurations and the containers with which the Pods will run. Besides writing this YAML file, you also need to build a Docker image for the Pods and make sure your data is available to them as well.
In this course, you will see how you can avoid all this hassle just by calling a Kale API from within your Kubeflow development environment.
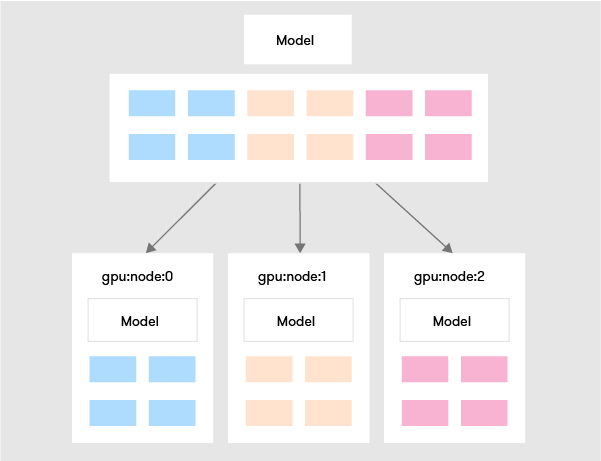
Data Parallelism
In a data-parallel method, the entire model is deployed to multiple nodes of a cluster and the data is sharded (horizontally split). Each instance of the model works on a part of the data.
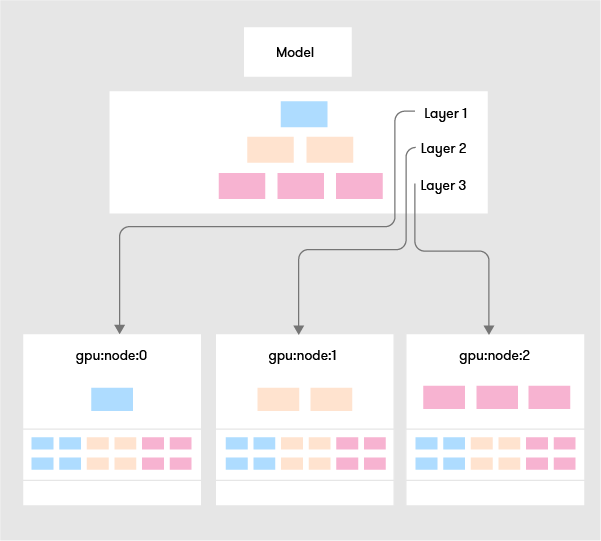
Model Parallelism
In the Model parallel method, a layer (or group of layers) of the model is deployed on one node of a cluster, and the whole data is copied to the node, each node trains on the complete dataset.
Centralized and Decentralized Training
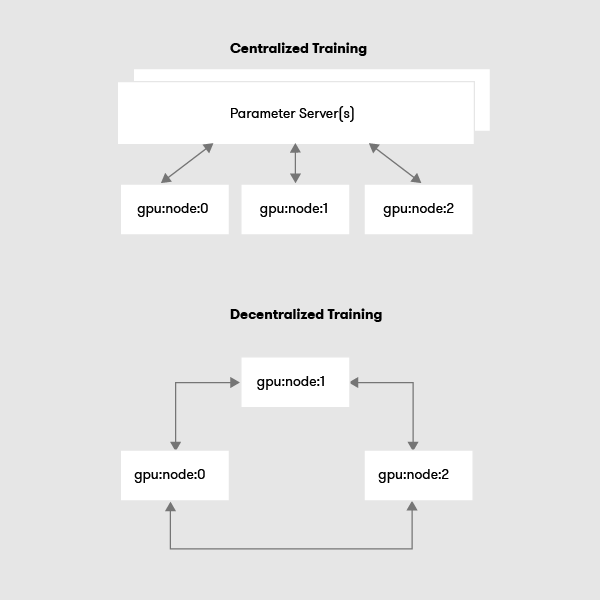
In a centralized communication pattern, there exists a node or group of nodes responsible for synchronizing the model parameters, this node is called a parameter server. The advantage of this approach is the ease to synchronize the model parameters, on the flip side the parameter server can itself become a bottleneck for a huge cluster. It is also a single point of failure. But of course, the bottleneck problem can be reduced to some extent by introducing multiple parallel servers and ensuring proper storage redundancy is applied.
In the decentralized communication pattern, each node communicates with every other node to update the parameters. The advantage of this approach is that peer-peer updates are faster, sparse updates can be made by exchanging only what has changed and there is no single point of failure.