Serve the Model and View the Training Logs
Now that we have found the best configuration and performed hyperparameter optimization on it, we have an easy way to serve the corresponding trained model.
Serve the Blue Book for Bulldozers Model
(Hands-On) Create a KF Serving Inference Server
As we described previously, Kale logs MLMD artifacts in a persistent way using Rok snapshots. This means that we have a snapshot of the best-performing model, as well as a snapshot of all the other trained models.
1. Go to the ML Metadata of the run-sklearn-transformer step.
Click on the run-sklearn-transformer step and go to the ML Metadata tab:
![]()
2. View the Outputs
Look at the Outputs and you will see the transformer. Notice that it has a unique Artifact ID. In our case, the ID is 11, but this will be different in your case:
![]()
3. Copy the Artifact ID
Copy this Artifact ID, as we are going to need it later.
4. Go to the ML Metadata of the train-sklearn-estimator step.
Click on the train-sklearn-estimator step and go to the ML Metadata tab:
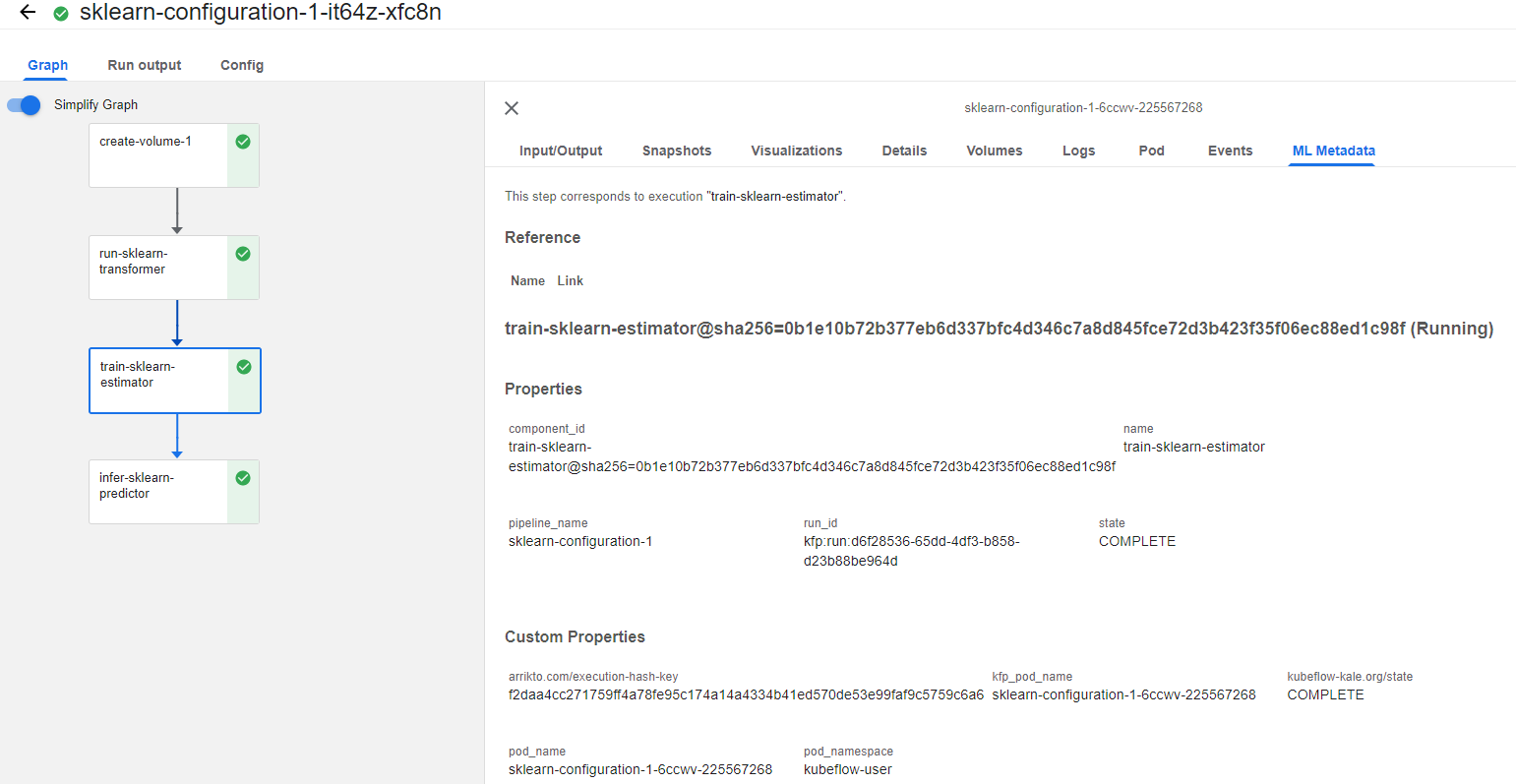
5. View the Outputs
Look at the Outputs and you will see the model. Notice that it has a unique Artifact ID. In our case, the ID is 17, but this will be different in your case:
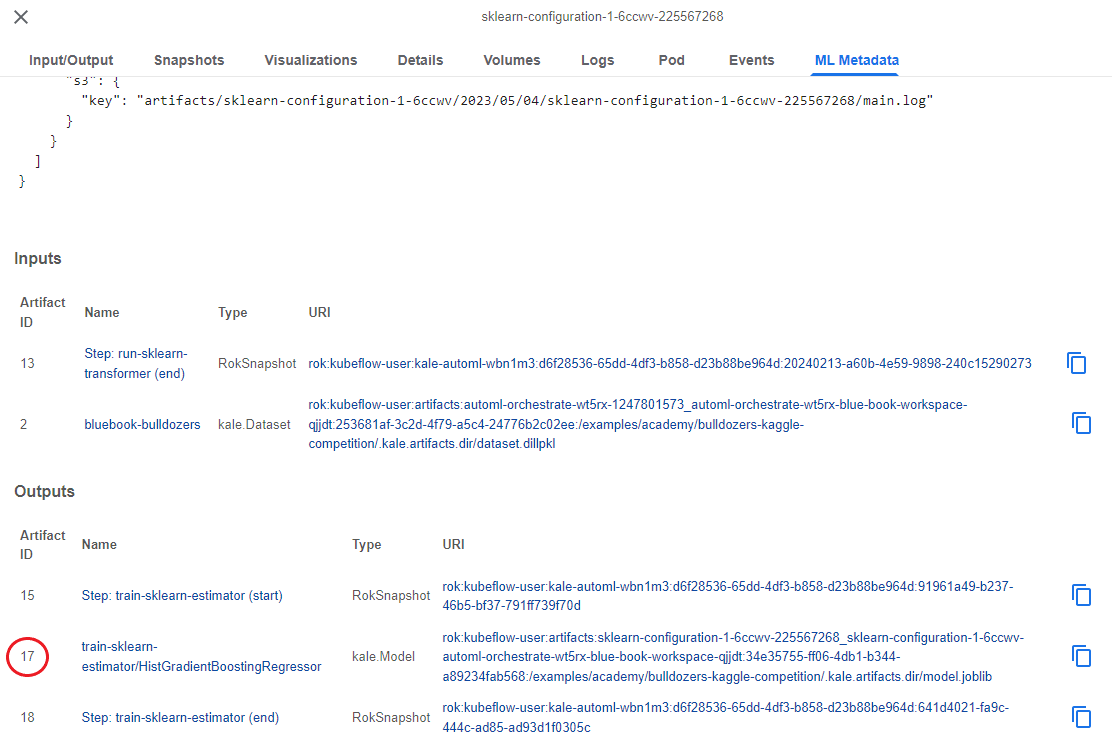
6. Copy the Artifact ID
Copy this Artifact ID, as we are going to need it later.
7. Go to the notebook
Let’s go back to the notebook and find this cell:
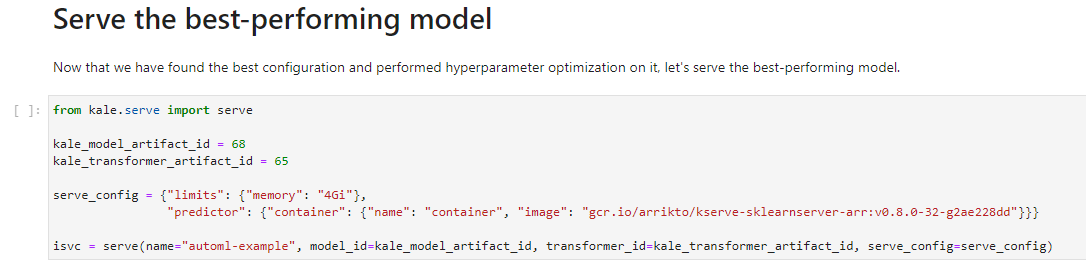
8. Paste the Artifact IDs
Replace the placeholders with the Artifacts IDs you copied earlier and run the cell:
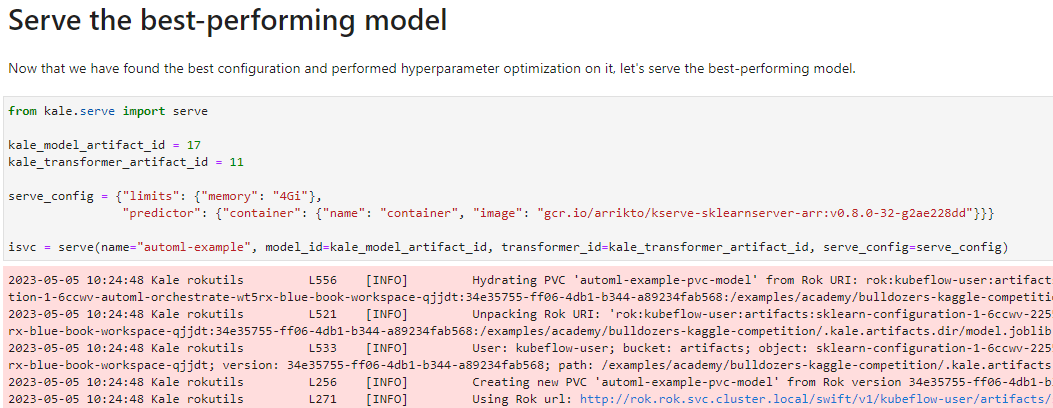
This will trigger Kale to create a new PVC that backs this model, configure and create a new KF Serving inference server, and apply it. In just a few seconds you will have a model running in Kubeflow!
1. Go to the ML Metadata of the train-sklearn-estimator step
To find the best-performing model and serve it, click on the train-sklearn-estimator step and go to the ML Metadata tab:
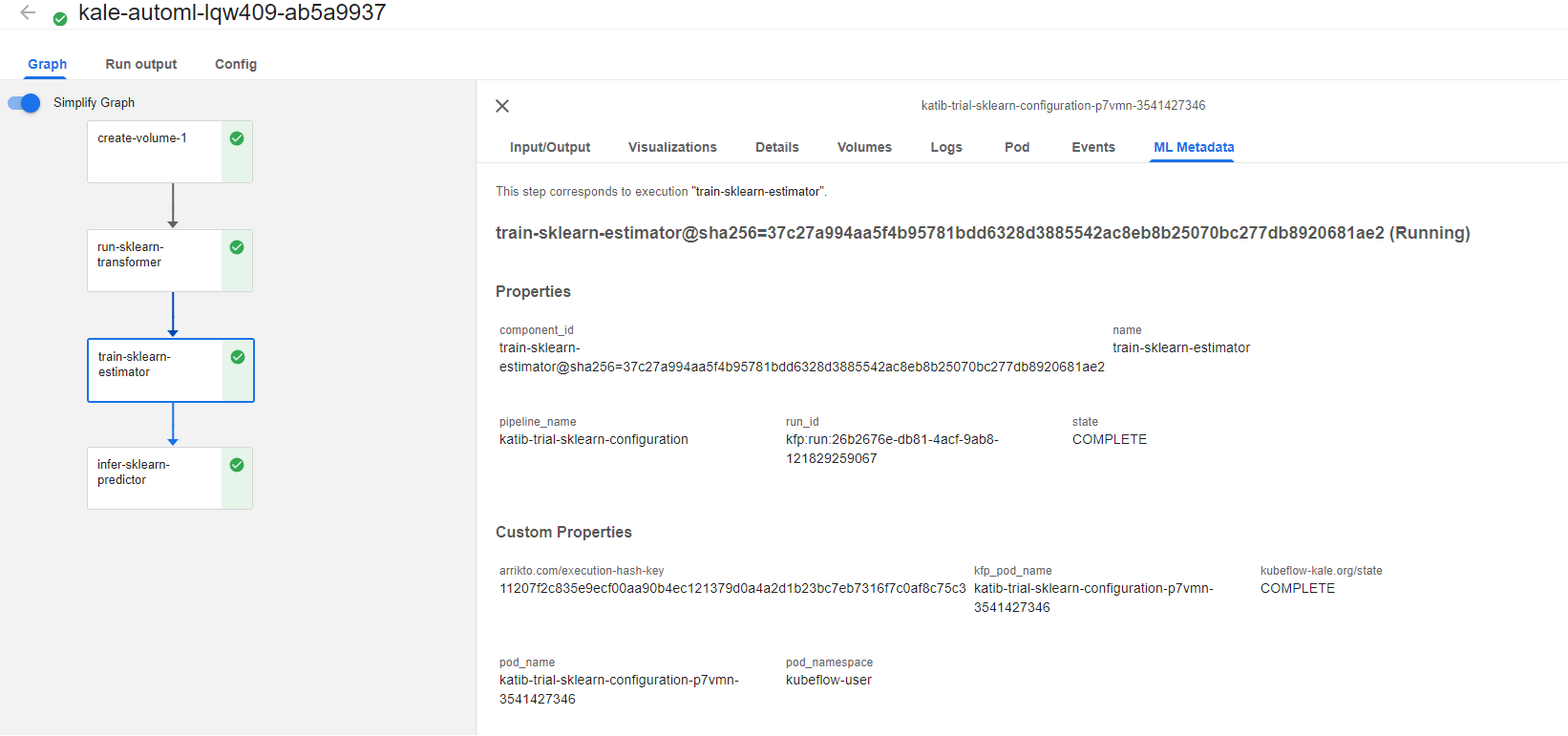
2. View the Outputs
Look at the Outputs and you will see the model. Notice that it has a unique Artifact ID. In our case, the ID is 203, but this will be different in your case:
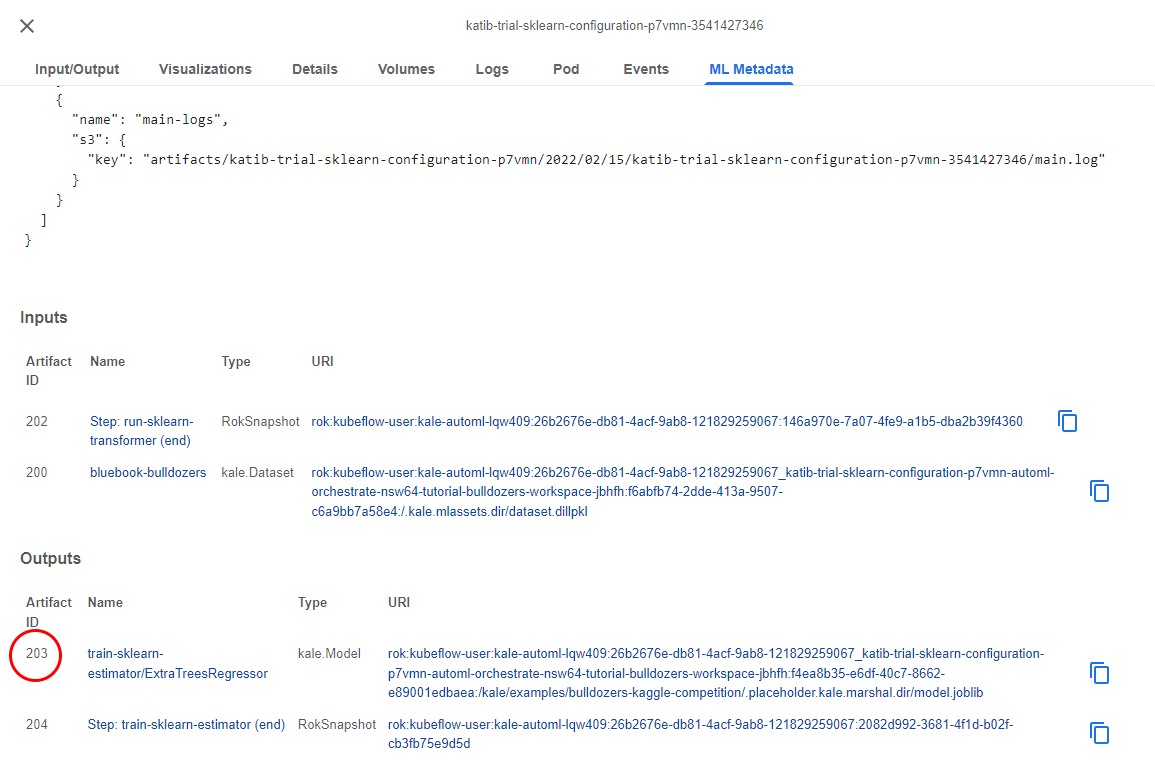
3. Copy the Artifact ID
Copy this Artifact ID, as we are going to need it to serve the model.
4. Go to the notebook
Let’s go back to the notebook and find this cell:
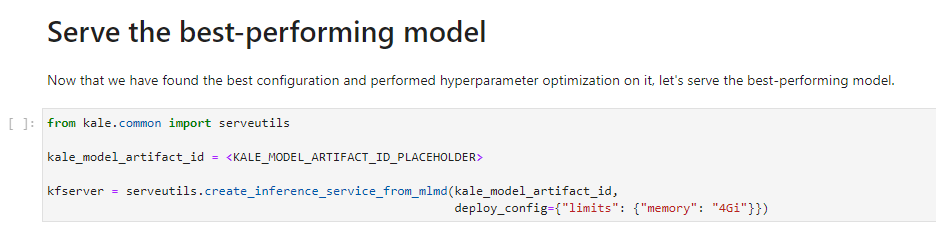
5. Paste the Artifact ID
Replace the placeholder with the Artifact ID you just copied and run the cell:
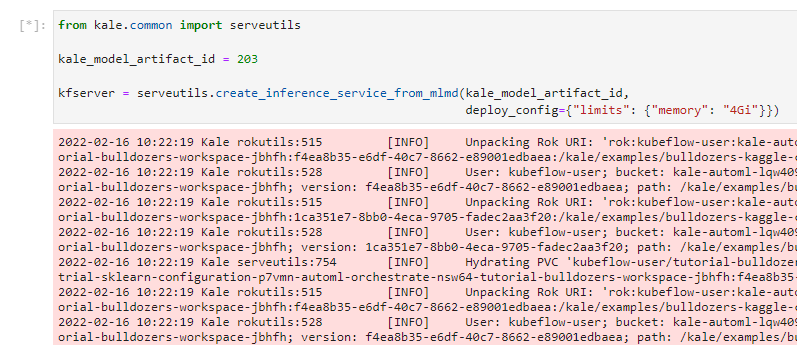
This will trigger Kale to create a new PVC that backs this model, configure and create a new KF Serving inference server, and apply it. In just a few seconds you will have a model running in Kubeflow!
(Hands-On) View the Inference Server
1. View the server
Run the next cell to see where the model is served:
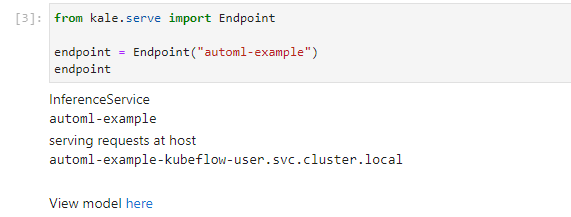
2. Navigate to the Models UI
Click on here to navigate to the Models UI:
3. View the model you served
This is the model you just served:
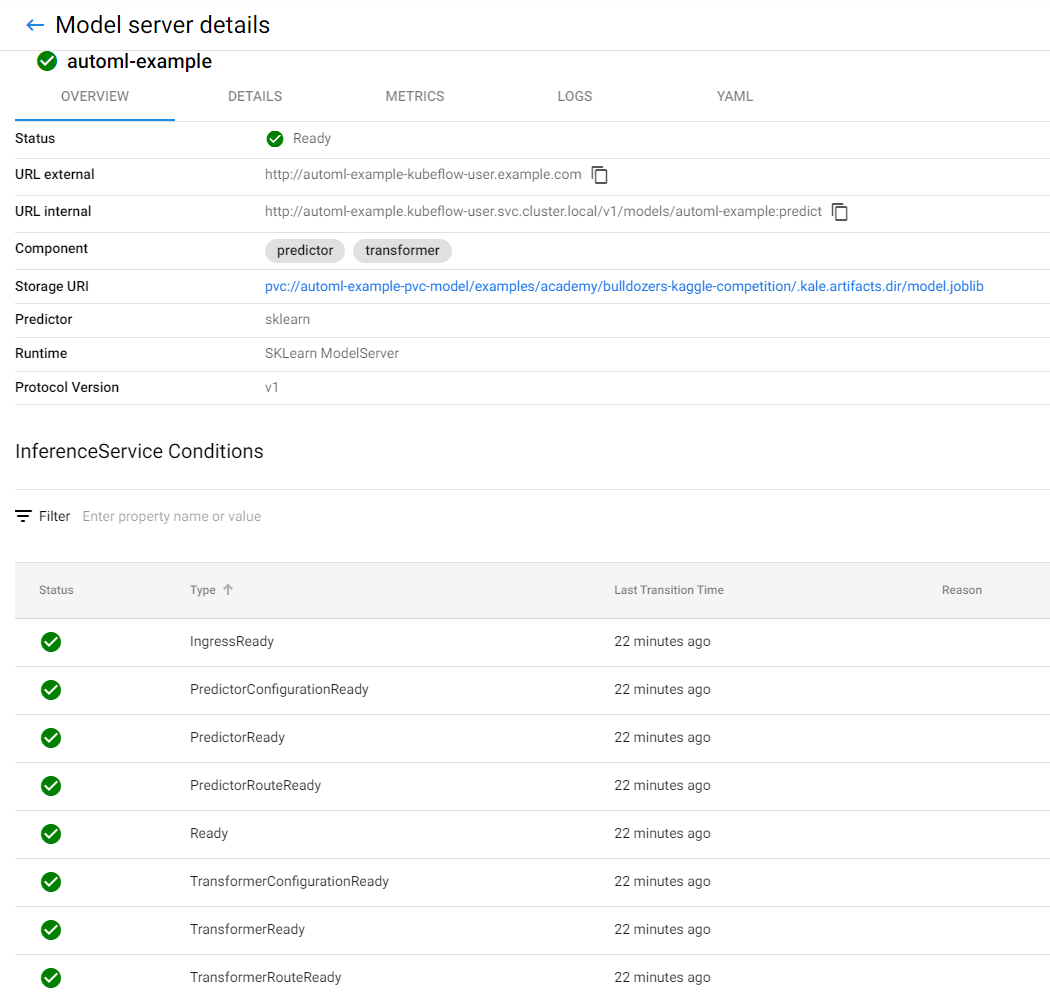
You have successfully served the best-performing model from inside your notebook! Now, let’s run some predictions against it.
1. View the server
Run the next cell to see where the model is served:
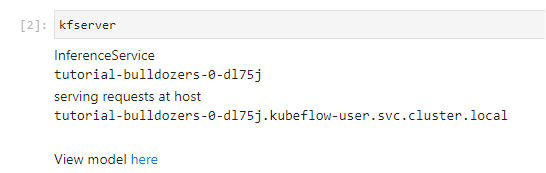
2. Navigate to the Models UI
Click on here to navigate to the Models UI:
3. View the model you served
This is the model you just served:
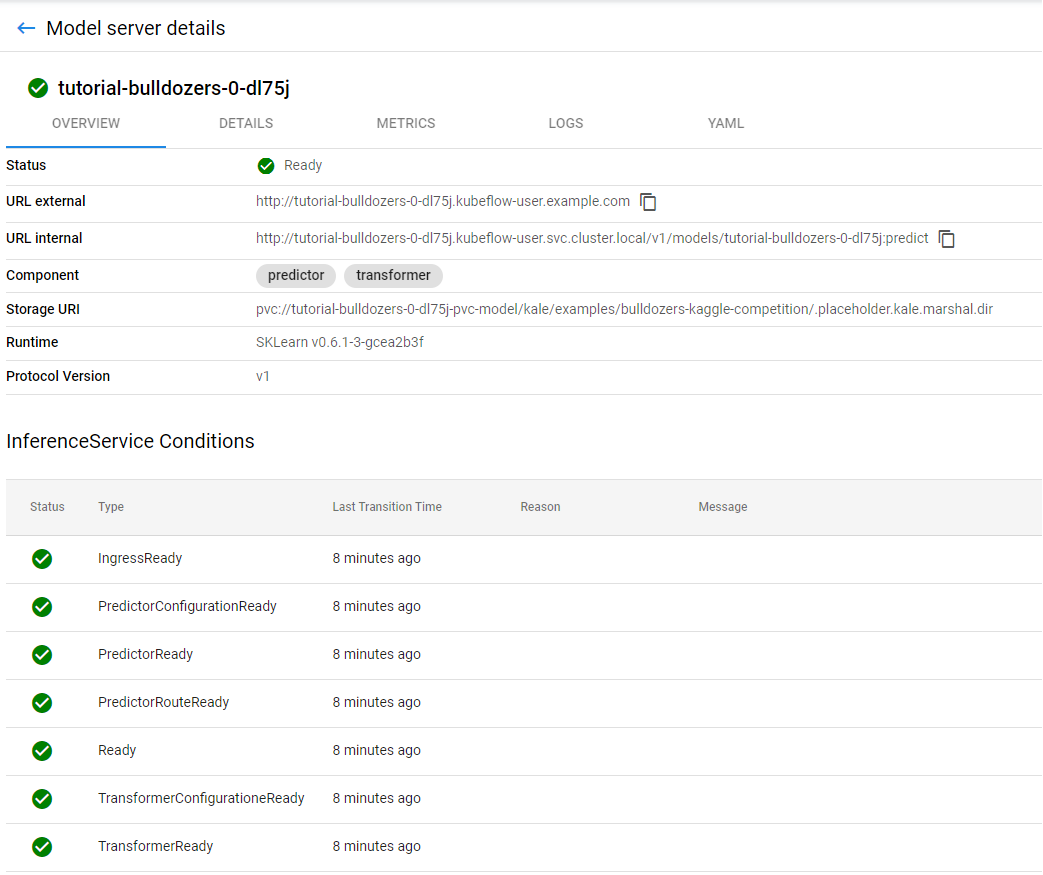
You have successfully served the best-performing model from inside your notebook! Now, let’s run some predictions against it.
(Hands-On) Run Predictions Against the Model
1. Go to the notebook
Go back to the notebook and run this cell:
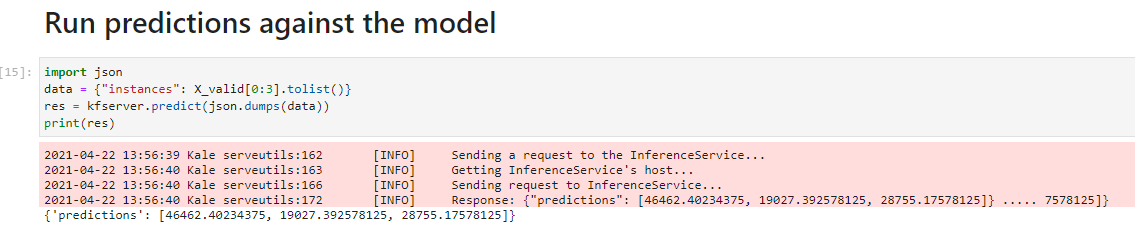
Congratulations! You have successfully created a KF Serving inference server that serves the best-performing model and runs predictions against it.
Create a TensorBoard Server and View Logs
Besides training and saving models, Kale also produces Tensorboard reports for each and every pipeline. Kale versions and snapshots reports using Rok and creates corresponding MLMD artifacts.
(Hands-On) Create a TensorBoard Server and View Logs
1. Go to the KFP run
Let’s go back to the KFP run that trained the best-performing model to view the ML Metadata tab of the sklearn-predictor step:
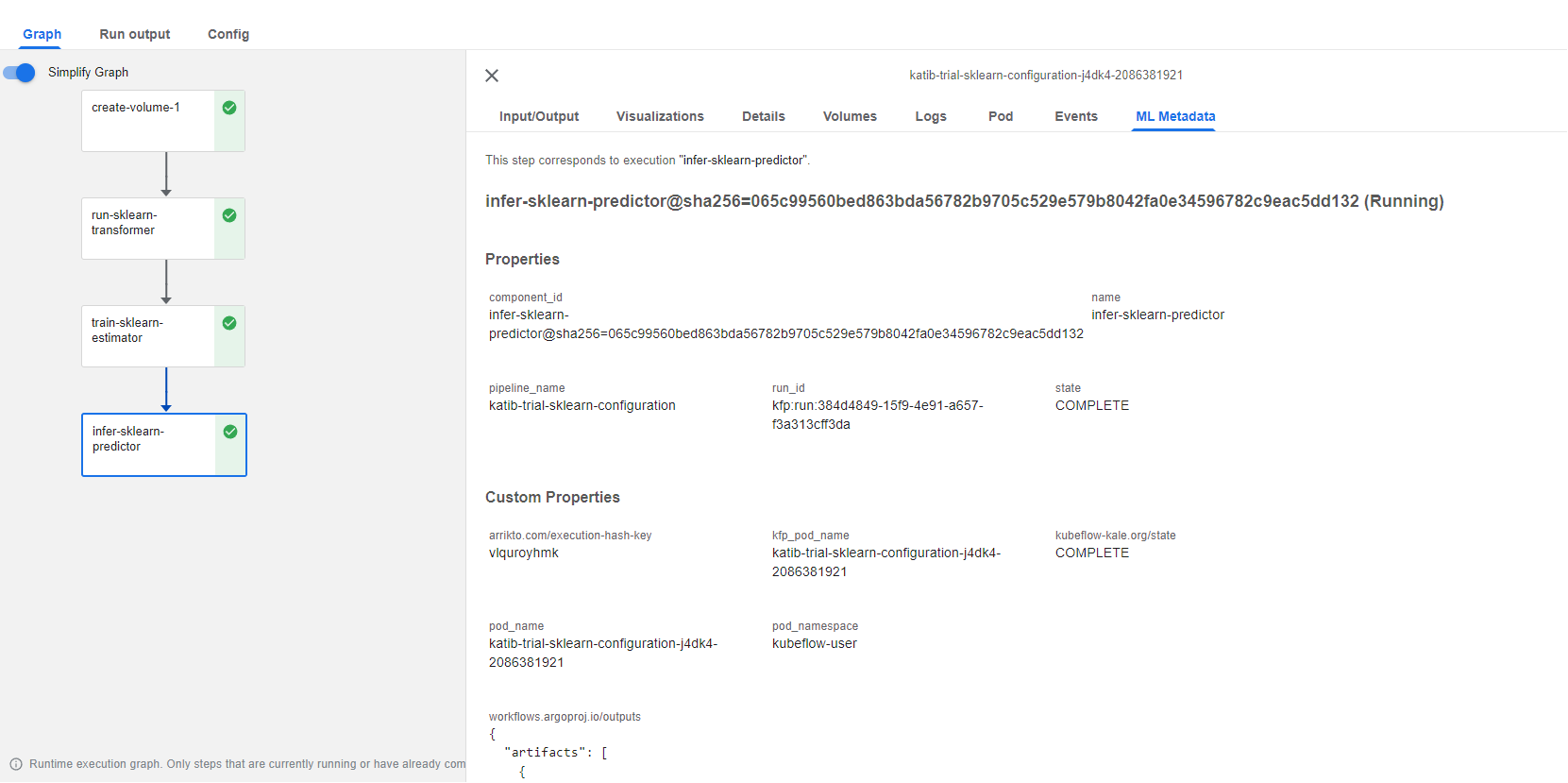
2. Find the TensorboardLogs artifact
Scroll down to the Outputs to find the TensorboardLogs artifact:
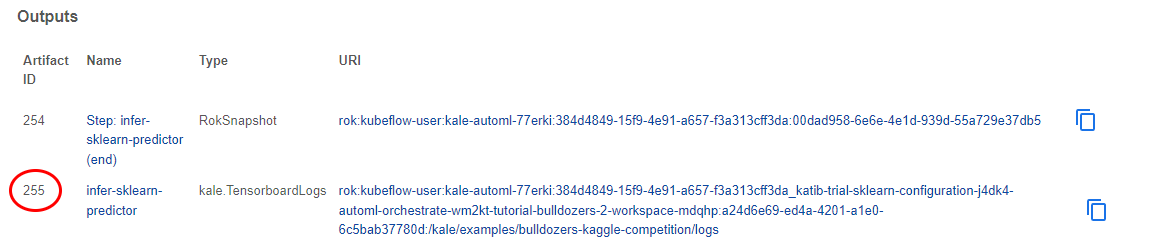
3. Copy the Artifact ID
Copy its Artifact ID, as you are going to need it to start the TensorBoard server from inside your notebook.
4. Go to the notebook
Go back to the notebook and find this cell:

5. Paste the Artifact ID
Replace the placeholder with the Artifact ID you just copied and run the cell:
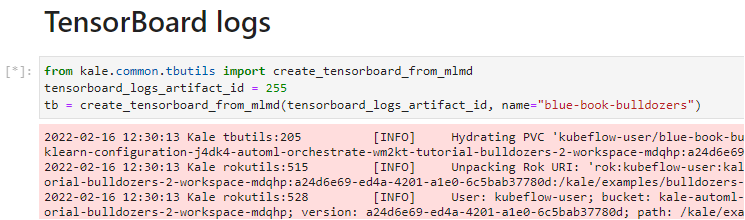
Wait for a few minutes for the TensorBoard server to get up and running. Kale is now creating a TensorBoard server that is backed by a Rok PVC.
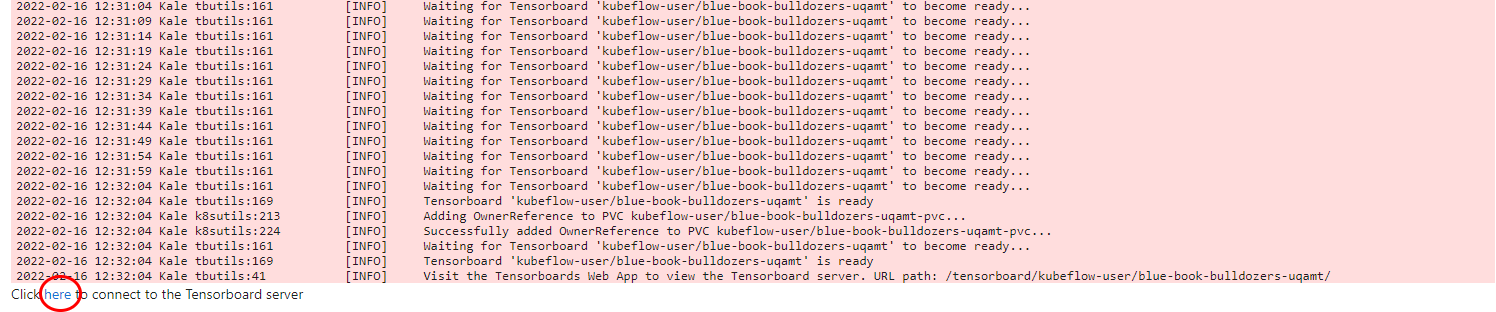
6. View the Tensorboard server
Click on the the here link to view the Tensorboard server you just created:
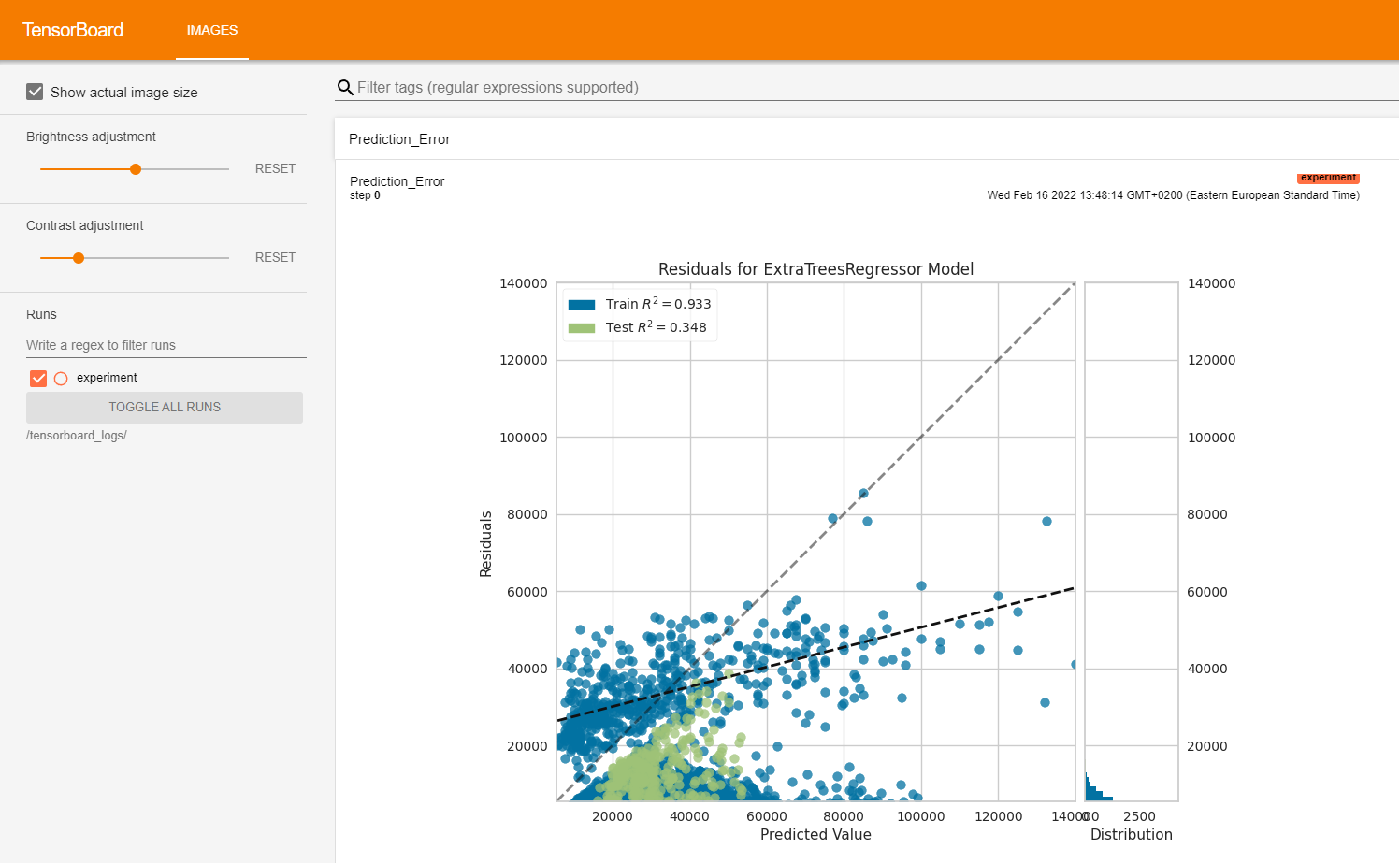
7. View the TensorBoard logs
Here are the logs that TensorBoard provides. We see the prediction error for the extra trees regression algorithm: