Kaggle, Kubeflow and MLOps
Kaggle and Blue Book for Bulldozers
Kaggle is an online community of Data Scientists, ML Engineers and MLOps champions who come together to explore creating models and technical solutions to popular real-world problems. Kaggle competitions focus on finding solutions to these popular problems to advance the collective community’s knowledge and capabilities. The notebook you will ork with is based on a Kaggle project with a goal to predict the sale price of a piece of heavy equipment at auction based on its usage, equipment type, and configuration. The data is sourced from auction result postings and includes information on usage and equipment configurations The model should create a “Blue Book for Bulldozers,” so people can better understand what price their heavy equipment fleet will bring at auction. This course is a self-service exploration of this problem solved using a Jupyter Notebook and Kubeflow Pipelines.
What is MLOps and Why is it Important?
Machine learning is becoming more and more ubiquitous across all manner of companies from start-ups to global enterprises. Enterprises are attempting to solve real-world business problems through Machine Learning and AI and this cutting-edge approach to business results in new challenges. Data Scientists are building state-of-the-art models using the Model Development Life Cycle. As a reminder, the overall Model Development Life Cycle can be summarized as:
- ML Development: experiment and develop a robust and reproducible model training procedure (training pipeline code), which consists of multiple tasks from data preparation and transformation to model training and evaluation. Typically Data Scientists begin with data transformation and experimentation in IDEs, such as JupyterLab Notebooks to review model quality metrics and identify models for further development or training. Data Scientists train their ideal models in development, using tools like HP Tuning or AutoML, to prepare the model for production.
- Training Operationalization: automate the packaging, testing, and deployment of repeatable and reliable training pipelines.
- Continuous Training: repeatedly execute the training pipeline in response to new data, code changes, or on a schedule, potentially with new training settings.
- Model Deployment: package, test, and deploy a model to a serving environment for online experimentation and production serving. An MLOps engineer takes the model creation pipeline from the Data Scientist and deploys the creation, serving, and validation of the model and supporting services into a production environment.
- Prediction Serving: serve the production model via an inference server exposed via a cloud endpoint.
- Continuous Monitoring: monitor and measure the efficacy and efficiency of a deployed model.
- Data and Model Management: this is a central, cross-cutting function for governing ML artifacts to support auditability, traceability, and compliance. Data and model management can also promote shareability, reusability, and discoverability of ML assets.
Data Scientists are supported by Data Engineers who are responsible for sourcing and cleaning data used for model development. ML Engineers are responsible for moving models into production and setting up monitoring to hedge the impact of changes in data profile or model drift. MLOps is focused on automating the testing and deployments of Machine Learning models while simultaneously improving the quality and integrity of the data considered in order to iterate on or create models in response to model drift and data profile changes. MLOps is a framework designed in response to the needs of the overall Model Development Life Cycle while adopting popular shift-left and “shift-right” concepts from traditional DevOps. MLOps demands that build tools allow us to ensure replicability, repeatability, reproducibility and that the data being considered is sourced properly and cleaned. If two people attempt to build the same product at the same revision number in the source code repository on different machines(or cloud environments), we should expect identical results. The build process must be self-contained and not rely on services external to the build environment. A portable, composable and resilient approach ensures consistency between development and production driving the velocity of the iterations. Keeping in mind that velocity can be at the cost of stability, the harmony between the two is critical. In general, MLOps is summarized as:
- An abstracted methodology to interface with specialized services to facilitate Model Development Lifecycle work, done efficiently in a decoupled manner.
- The ability to continuously build, train and improve models to ensure stability and accuracy during production.
- Strategies and processes to repeatedly transform raw datasets, produce predictive features and respond to business goals.
- An environment that handles the life cycle of continuous training pipelines and resulting models as well as monitoring the quality of prediction results.
All in all, MLOps is a unified vision and automated Continuous Training process which cycles through points 1 - 4 above to improve the model in response to ever-evolving business needs.
The goal of MLOps is to deploy the model and achieve ML model lifecycle management holistically across the enterprise, reducing technical friction, and moving into production with as little risk and as rapidly to market as possible. A model has no ROI until it is running in production. As with any process, we track a variety of KPIs to evaluate the performance of our MLOps environment and the overall process.
- Commits / Day / Data Scientist: How frequently can a team update Pipeline code?
- Development Cycle Time: How long does work take, soup to nuts?
- Defect Rate: How often does a model need to be rollback / retrained?
- Mean Time to Repair: How quickly can a team redeploy or debug a failing or broken model?
- Mean time to Respond: How quickly can a team adjust to model drift or other external pressures?
While these are general health metrics to gauge the effectiveness of the MLOps environment and practice, keep in mind the end goal is to achieve a stable model in production. Targeting these metrics as the source of truth for model quality is not the goal, these metrics are used to inform the decision-making process around these models.
In order to work at scale, teams must be self-sufficient so that individual teams can decide how often and when to release new versions of their products. This is the intention of “shift-left” thinking that came about as part of DevOps and is being adopted by MLOps. Teams must also have confidence that their work does not create additional work for their peers, and that their MLOps platform facilitates both the control and collaboration necessary to catch issues early as well as minimize incurred technical debt. A selection must be based upon test results for the features selected for a given build. Release processes should be automated to the point that they require minimal involvement by the engineers, and multiple projects can be automatically built and released using a combination of the automated build systems and deployment tools. Additionally, it must be possible to track the lineage of the data used as well as the model creation process. In summary, the platform must enforce company-specific non-negotiables around security, reliability, and governance to protect against common human error mishaps that can lead to risky outcomes. This type of thinking is why MLOps is critical to enterprises looking to reduce technical debt and improve model development quality and deployment KPIs. Keep in mind that an effective and self-sustainable MLOps culture and environment is an ideal that many enterprises are marching towards with Kubeflow, therefore we will explore this discussion within the context of Kubeflow. Throughout this course, we will explore MLOps topics and discuss how mature MLOps deployments approach popular problems such as the one solved in this Kaggle Competition example.
Why Kubeflow for MLOps
Kubeflow is a Data Scientist obsessed platform that leverages the power of Kubernetes to improve the Model Development Lifecycle by abstracting away the K8s complexity so Data Scientists can focus on data science. Kubeflow is a specialized ML platform that is built for Kubernetes and runs in Kubernetes clusters as a collection of Pods and Operators. Kubeflow harnesses the power of Kubernetes to orchestrate containerized environments allowing enterprises to optimize the path from development to production. Kubeflow provides a framework for Data Scientists to run ML services and workloads via IDEs, such as JupyterLab Notebooks, and serve these models using native Kubeflow functionality or by directly integrating with existing CI / CD processes.
Kubeflow also provides out-of-the-box lineage tracking of the data artifacts used to create models as well as the exact model creation process. This is critical for auditing, reproduction, and governance of the environment and acceptance of models into production environments. Using the Kubeflow platform reduces the friction that Data Scientists and other MLOps professionals face daily, allowing for greater collaboration, and reducing model time to production. Migrating to Kubeflow, or managing and paying down your technical debt, introduces long-term stability, increases reusability, improves quality, and decreases future maintenance. This first step is the most crucial because you are choosing to invest in your future technology stack.
From a technical perspective, Kubeflow components run within the Kubernetes Pods. The Pod is the main unit of scheduling in Kubernetes, it runs containers and can request specific compute resources. A pod may request K8s to provision a large pool or memory, a huge data volume, or a GPU. These requests happen behind the scenes and the data scientist doesn’t have to worry about these compute resources finding their way into their workloads. Notable Data Science centric workloads that run within Pods are Notebook Servers, Kubeflow Pipeline steps, distributed jobs, and served models. These workloads assume K8s will seamlessly schedule them across the cluster nodes based on their compute requirements thus improving efficiency and resilience. Kubeflow and Kale allow data scientists to focus only on model development while letting the underlying components deal with the provisioning and scheduling of resources. Once you’ve made this choice you are on an exciting journey along with the Open Source community and the large number of enterprises that have selected Kubeflow as their MLOps platform. As a result of Kubeflow’s obsession with Data Science, it is the fastest and best way to quickly iterate on a model. While there are multiple ways to solve this ML problem, none will provide the same foundation as Kubeflow. Choosing Kubeflow as your platform establishes the foundation for a robust MLOps environment in support of a long-term production solution. Therefore as you explore MLOps you will do so using Kubeflow and the associated technical components that make the Model Development Life Cycle possible and set the foundation for Continuous Testing, Integration, and Deployment.
Why Kubeflow as a Service for Kaggle & MLOps
MLOps is made possible with a technical foundation built upon Kubeflow. Kubeflow is a Data Scientist obsessed platform that leverages the power of Kubernetes to improve the Model Development Lifecycle by abstracting away the K8s complexity. Simply put, Kubeflow makes it easier for Data Scientists to focus on data science. Using the Kubeflow platform reduces the friction that Data Scientists and MLOps professionals face daily, allowing for greater collaboration and reducing model time to production. Migrating to Kubeflow, and paying down your technical debt, introduces long-term stability, increased reusability, improved quality, and decreased future maintenance.
As a reminder, an effective and self-sustainable MLOps culture and environment built upon Kubeflow using Kubeflow Pipelines is characterized by:
- An abstracted methodology to interface with specialized services to get Model Development Lifecycle work done efficiently in a decoupled manner.
- The ability to continuously build, train and improve models to ensure stability and accuracy during production.
- Strategies and processes to repeatedly transform raw datasets, produce predictive features, and respond to business goals.
- An environment that handles the life cycle of continuous training pipelines and resulting models as well as monitoring the quality of prediction result.
All in all, MLOps is a unified vision and automated Continuous Training process which cycles through points 1 - 4 above to improve the model in response to ever-evolving business needs. This approach, once adopted, maximizes both the velocity of model development as well as the resilience and reliability of the overall system. The reduction in friction/toil helps organizations achieve a reduction in hours committed to work that is manual, repetitive, and has no intrinsic value to the organization.
Individuals interested in exploring Kaggle challenges or even solving new ones should start with Kubeflow since it is the fastest and best way to quickly iterate on a model for any problem presented in a Kaggle Competition. While there are multiple ways to solve this problem, none will provide the same foundation for a MLOps practice and culture as Kubeflow. Fortunately for the Kaggle community, the data provided and used is already consolidated, cleansed, and transformed. Typically this work would need to be done by a Data Engineer in advance of any Data Science work, however, that step will be skipped thanks to the work of the community. Therefore as you work through this course keep in mind that you are already one step into the Model Development Life Cycle.
This course and the hands-on activity will all take place in Kubeflow as a Service where you will have access to a full Kubeflow deployment in a single click! Kubeflow as a Service is the fastest way to get up and running with Kubeflow and take your first step towards an MLOps culture and environment for your enterprise. Throughout this course, we will continue to acknowledge how the activities you are performing in Kubeflow as a Service relate to and reflect on what will happen as you migrate to a full MLOps environment. As you proceed beyond this course in your MLOps journey you will continue to use Kubeflow as a Service, until you move to a fully managed Enterprise Kubeflow as a Service or another equivalent type of deployment.
If you have already deployed a Kubeflow as a Service Instance or are using Enterprise Kubeflow you can proceed to the next section.
(Hands-On) Kubeflow as a Service
1. Log in to Kubeflow as a Service
In your browser navigate to kubeflow.arrikto.com and complete the sign-up and sign-in process. Upon login, you will see the landing screen.

2. Create New Kubeflow Deployment
Select the + New Kubeflow Deployment option in the top right corner
Click the Create button in the pop-up.
3. Watch the video
While waiting for your Kubeflow Deployment, watch the video on Kubeflow as a Service to familiarize yourself with the tool.
Once you have completed the video select close.
4. View Login Information
The deployment status will appear as Running when the deployment is ready.

Select the view option to see the login details for your Kubeflow Deployment.
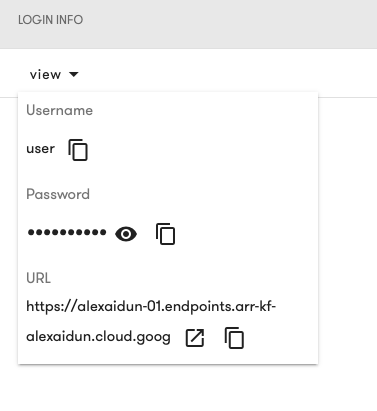
5. Log in to Kubeflow
Use the URL, username, and password provided to log in to your Kubeflow Deployment and view the landing page.
Congratulations! You have deployed Kubeflow. Please proceed with the next section
MLOps and The Model Development Life Cycle
Kubeflow Jupyter Notebooks facilitate the traditional Model Development Life Cycle within the proposed MLOps framework.
ML Development: experiment and develop a robust and reproducible model training procedure (training pipeline code), which consists of multiple tasks from data preparation and transformation to model training and evaluation. Typically Data Scientists begin with data transformation and experimentation in IDEs, such as JupyterLab Notebooks to review model quality metrics and identify models for further development or training. Data Scientists train their ideal models in development, using tools like HP Tuning or AutoML, and prepare the model for production.
Training Operationalization: automate the packaging, testing, and deployment of repeatable and reliable training pipelines.
Continuous Training: repeatedly execute the training pipeline in response to new data or to code changes, or on a schedule, potentially with new training settings.
Model Deployment: package, test, and deploy a model to a serving environment for online experimentation and production serving. An MLOps engineer takes the model creation pipeline from the Data Scientist and deploys the creation, serving, and validation of the model and supporting services into a production environment.
Prediction Serving: serve the production model via an inference server.
Continuous Monitoring: monitor and measure the effectiveness and efficiency of a deployed model.
Data and Model Management: is a central, cross-cutting function for governing ML artifacts to support auditability, traceability, and compliance. Data and model management can also promote shareability, reusability, and discoverability of ML assets.
Taking a step back, before Data Scientists even perform data exploration the data must be cleansed so that the best data is provided. Clean and high-quality data drives high-quality models and this is the goal of any Model Development Life Cycle. Data Scientists are supported by Data Engineers who are responsible for sourcing and cleaning data used for model development. ML Engineers are responsible for moving models into production and setting up monitoring to hedge the impact of changes in data profile or model drift. MLOps is focused on automating the testing and deployments of Machine Learning models while simultaneously improving the quality and integrity of the data considered to create the models in response to model drift and data profile changes.
For data exploration, Data Scientists will take a subset of available data into a personal environment, in this case, Jupyter Notebooks, to evaluate data quality and identify patterns. Based on their domain expertise, statistical analysis, and vast algorithmic knowledge, Data Scientists then determine how to proceed with model creation. Performing this activity within the storage of the Kubeflow Notebook reduces the burden on the network to continually pull new data from a central repository, such as S3 or some other Data Lake. Executing computations for data exploration as close to the Data Scientist as possible, specifically in the Jupyter Notebook or local pipeline volume, reduces overall resource consumption in the system and allows Kubeflow to leverage Kubernetes optimization on behalf of the Data Scientist. In this course, you will replicate this exact step since you will download the data directly into your Jupyter Notebook on the Notebook Server.
Once the desired features for model development have been identified Data Scientists will need to standardize, globally across the organization, on not just the features but how the features are transformed from the source data. This is necessary because Data Lakes are volatile and mutable and are typically designed for high-quality data inputs for dashboards or business intelligence visualizations. Data Lakes can be standardized for the Model Development Life Cycle, however, a Feature Store is not only optimized but designed for this purpose. Consider the Feature Store as the versioned, consolidated, and standardized input for model development, training, and tuning. In this course you will not be working with a feature store, this will be done in the personal Jupyter Notebook. However, in a mature MLOps environment, the Jupyter Notebook should query the Feature Store to get the feature list for model development.
With the features identified based on Data Exploration and, if possible the Feature Store, it is time to create the actual machine learning model. This is also done in the Jupyter Notebook and this happens initially with the data that was pulled into the Notebook Server. However, in a mature MLOps environment, you should expect to pull fresh data from the desired External Data Source as per the Features identified in the Feature Store for the model. In this course, you will do initial model training with the Jupyter Notebook however once a model has been developed you will want to implement a Continuous Training process to ensure the model is always up to date with the latest data. You will explore Continuous Training further towards the end of this course. One of the core tenets of MLOps, which is borrowed from DevOps, is to perform as much testing as possible early so as to improve velocity and reduce future maintenance needs. Test-driven deployments with unit tests written by the developers as part of the model creation process ensure early validation of high functioning and quality models. Making changes to a model, or any step in the model creation process becomes more expensive the closer the model gets to deployment and production. Data Scientists use model quality evaluation frameworks and algorithms to compare and contrast model performance. However, in a mature MLOps environment, this step should be further automated so that as models pass the quality inspection they are made immediately available to subsequent deployment processes. In this course, you will manually evaluate the quality of the models. However, in practice, you will want to implement a Continuous Training process to ensure the highest quality model is selected. You will explore Continuous Training further towards the end of this course.
Once an ideal model has been identified based on model training and testing, Data Scientists will perform Hyperparameter Tuning to make sure the model is as finely tuned as possible. Hyperparameter Tuning and other AutoML activities will be orchestrated from within the Jupyter Notebook as well. In this course, you will manually Hyperparameter Tune the models. In practical application, you will want to implement a Continuous Training process to ensure the highest quality model is finely tuned. You will explore Continuous Training further towards the end of this course.
Jupyter Notebooks are the vehicle for MDLC for Data Scientists in Kubeflow because they abstract away the complexities of both Kubeflow and Kubernetes so that Data Scientists can focus exclusively on their work. Kubeflow project namespaces provide an isolated personal environment, however, this is only the beginning of the overall MLOps process. Once this work is done, Data Scientists can quickly create, compile, and run a Kubeflow Pipeline. Since Kubeflow Pipelines are snapshotted and can be shared, the output of the Model Development Life Cycle is not just a model, but a process by which to continually train the desired model in any environment. With such a Continuous Training process implemented additional processes around Continuous Integration of the approved best-tuned model and Continuous Deployment of the model in production can be developed. These are the foundations of MLOps and the concepts that Kubeflow and Kubeflow Pipelines are supporting. We will explore the rest of these concepts throughout the course. In this section, we will proceed with Data Exploration, Feature Selection, and Model Creation by deploying a Kubeflow Pipeline.